This ends up with a matched pairs test after tidying.
Introduction
Some cars have a computer that records gas mileage since the last time the computer was reset. A driver is concerned that the computer on their car is not as accurate as it might be, so they keep an old-fashioned notebook and record the miles driven since the last fillup, and the amount of gas filled up, and use that to compute the miles per gallon. They also record what the car’s computer says the miles per gallon was.
Is there a systematic difference between the computer’s values and the driver’s? If so, which way does it go?
Packages
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.6
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.1 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.2
✔ purrr 1.2.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
The data
The driver’s notebook has small pages, so the data look like this:
This is not very close to tidy. There are three variables: the fillup number (identification), the computer’s miles-per-gallon value, and the driver’s. These should be in columns, not rows. Also, there are really four sets of rows, because of the way the data was recorded. How are we going to make this tidy?
Making it tidy
As ever, we take this one step at a time, building a pipeline as we go: we see what each step produces before figuring out what to do next.
The first thing is to read the data in; these are aligned columns, so read_table is the thing. Also, there are no column headers, so we have to say that as well:
I usually find it easier to make the dataframe longer first, and then figure out what to do next. Here, that means putting all the data values in one column, and having a column of variable names indicating what each variable is a value of, thus:
gas %>%pivot_longer(X2:X6, names_to ="var_name", values_to ="var_value")
The things in X1 are our column-names-to-be, and the values that go with them are in var_value. var_name has mostly served its purpose; these are the original columns in the data file, which we don’t need any more. So now, we make this wider, right?
Warning: Values from `var_value` are not uniquely identified; output will contain
list-cols.
• Use `values_fn = list` to suppress this warning.
• Use `values_fn = {summary_fun}` to summarise duplicates.
• Use the following dplyr code to identify duplicates.
{data} |>
dplyr::summarise(n = dplyr::n(), .by = c(var_name, X1)) |>
dplyr::filter(n > 1L)
Oh. How did we get list-columns?
The answer is that pivot_wider needs to know which column each var_value is going to, but also which row. The way it decides about rows is to look at all combinations of things in the other columns, the ones not involved in the pivot_wider. The only one of those here is var_name, so each value goes in the column according to its value in X1, and the row according to its value in var_name. For example, the value 41.5 in row 6 of the longer dataframe goes into the column labelled Computer and the row labelled X2. But if you scroll down the longer dataframe, you’ll find there are four data values with the Computer-X2 combination, so pivot_wider collects them together into one cell of the output dataframe.
This is what the warning is about.
spread handled this much less gracefully:
gas %>%pivot_longer(X2:X6, names_to ="var_name", values_to ="var_value") %>%spread(X1, var_value)
Error in `spread()`:
! Each row of output must be identified by a unique combination of keys.
ℹ Keys are shared for 60 rows
• 6, 21, 36, 51
• 7, 22, 37, 52
• 8, 23, 38, 53
• 9, 24, 39, 54
• 10, 25, 40, 55
• 11, 26, 41, 56
• 12, 27, 42, 57
• 13, 28, 43, 58
• 14, 29, 44, 59
• 15, 30, 45, 60
• 1, 16, 31, 46
• 2, 17, 32, 47
• 3, 18, 33, 48
• 4, 19, 34, 49
• 5, 20, 35, 50
Warning: Values from `var_value` are not uniquely identified; output will contain
list-cols.
• Use `values_fn = list` to suppress this warning.
• Use `values_fn = {summary_fun}` to summarise duplicates.
• Use the following dplyr code to identify duplicates.
{data} |>
dplyr::summarise(n = dplyr::n(), .by = c(var_name, X1)) |>
dplyr::filter(n > 1L)
There is a mindless way to go on from here, and a thoughtful way.
The mindless way to handle unwanted list-columns is to throw an unnest at the problem and see what happens:
Warning: Values from `var_value` are not uniquely identified; output will contain
list-cols.
• Use `values_fn = list` to suppress this warning.
• Use `values_fn = {summary_fun}` to summarise duplicates.
• Use the following dplyr code to identify duplicates.
{data} |>
dplyr::summarise(n = dplyr::n(), .by = c(var_name, X1)) |>
dplyr::filter(n > 1L)
Warning: `cols` is now required when using `unnest()`.
ℹ Please use `cols = c(Fillup, Computer, Driver)`.
This has worked.1 The fillup numbers have come out in the wrong order, but that’s probably not a problem. It would also work if you had a different number of observations on each row of the original data file, as long as you had a fillup number, a computer value and a driver value for each one.
The thoughtful way to go is to organize it so that each row will have a unique combination of columns that are left. A way to do that is to note that the original data file has four “blocks” of five observations each:
gas
Each set of three rows is one block. So if we number the blocks, each observation of Fillup, Computer, and Driver will have an X-something column that it comes from and a block, and this combination will be unique.
You could create the block column by hand easily enough, or note that each block starts with a row called Fillup and use this idea:
gas %>%mutate(block =cumsum(X1=="Fillup"))
This works because X1=="Fillup" is either true or false. cumsum takes cumulative sums; that is, the sum of all the values in the column down to and including the one you’re looking at. It requires numeric input, though, so it turns the logical values into 1 for TRUE and 0 for FALSE and adds those up. (This is the same thing that as.numeric does.) The idea is that the value of block gets bumped by one every time you hit a Fillup line.
Then pivot-longer as before:
gas %>%mutate(block =cumsum(X1=="Fillup")) %>%pivot_longer(X2:X6, names_to ="var_name", values_to ="var_value")
and now you can check that the var_name - block combinations are unique for each value in X1, so pivoting wider should work smoothly now:
Sometimes a pivot_longer followed by a pivot_wider can be turned into a single pivot_longer with options (see the pivoting vignette for examples), but this appears not to be one of those.
Comparing the driver and the computer
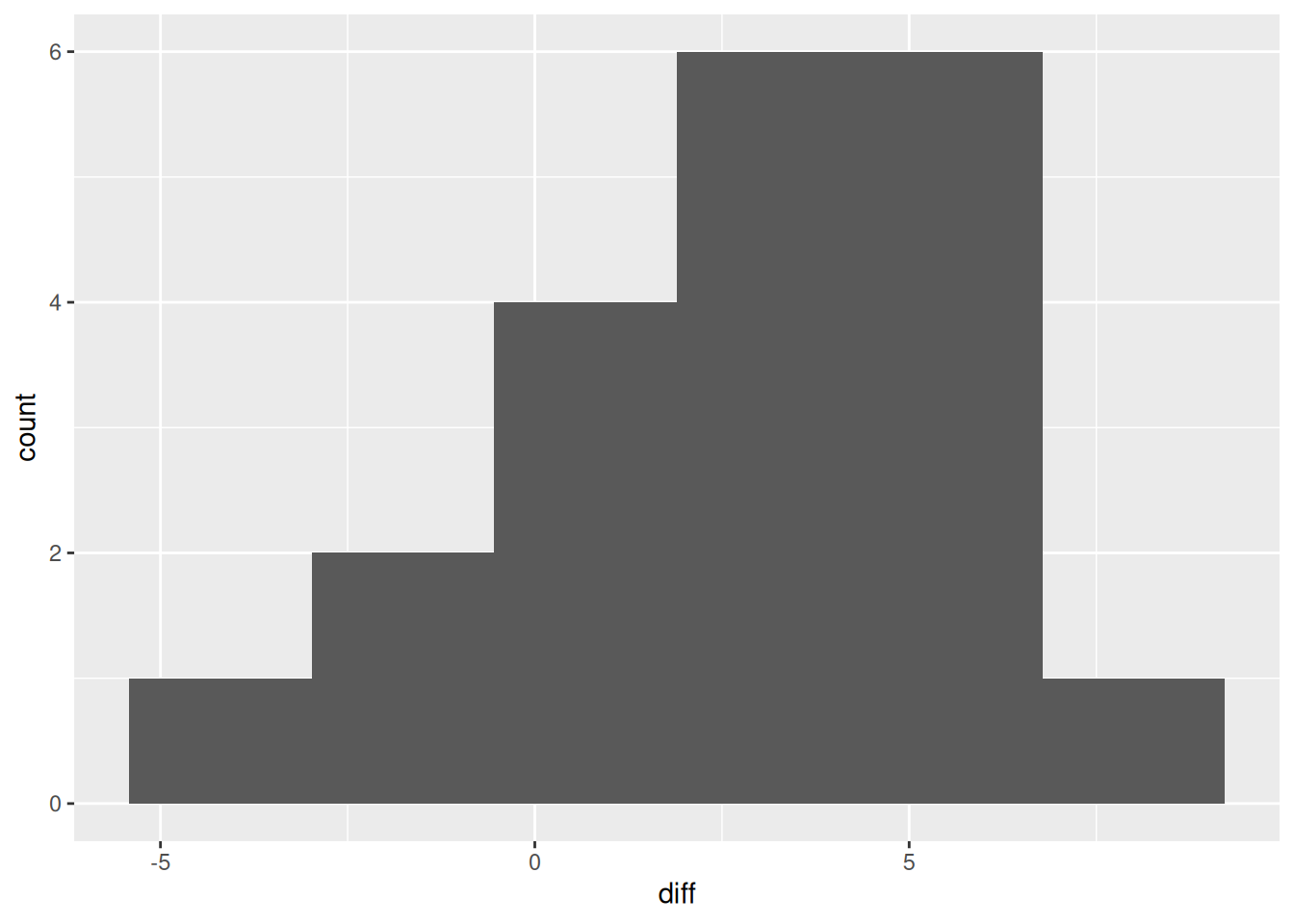
Now that we have tidy data, we can do an analysis. These are matched-pair data (one Computer and one Driver measurement), so a sensible graph would be of the differences, a histogram, say:
There is only one observation where the driver’s measurement is much bigger than the computer’s; otherwise, there is not much to choose or the computer’s measurement is bigger. Is this something that would generalize to “all measurements”, presumably all measurements at fillup by this driver and this computer? The differences are not badly non-normal, so a \(t\)-test should be fine:
Paired t-test
data: Computer and Driver
t = 4.358, df = 19, p-value = 0.0003386
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
1.418847 4.041153
sample estimates:
mean difference
2.73
It is. The computer’s mean measurement is estimated to be between about 1.4 and 4.0 miles per gallon larger than the driver’s.